
在中国数据库市场,比“替代”更难的是选择。
如今,数据库已成为AI时代名副其实的数据底座,但国内企业技术决策者们却陷入一种前所未有的“选择焦虑”:数据库市场品牌林立,技术架构同质化严重,上百款数据库产品更是目不暇接,以至于技术决策者们纷纷发出感叹:“为什么数据库选型这么难?”
毫无疑问,“选择困境”的背后是一个更深层的问题:即随着中国千行百业数智化转型的全面深入,数据库如何支撑起企业近、中和长期的数据战略需求?
对此,平凯星辰带来它的答案。在发布平凯数据库(TiDB企业版)两年多后,平凯数据库(TiDB企业版)发布了全新形态:基于同一套内核衍生的三种部署模式,以打破数据库选型“水平扩展、业务透明、极致性能”不可兼得的“不可能三角”,适配企业不同场景、不同战略阶段的数据需求。

选型“不可能三角”能否打破?
数据库使用周期通常达到8-10年。选对了,则企业数智化战略能够顺利落地;选错了,可能面临的就是一场漫长的技术噩梦。
对于中国用户而言,数据库选型更处于一个多重困难的交汇点:
- 近期之难在于“负重爬坡”:存量数据与应用的迁移,犹如上升飞行的飞机在空中更换引擎,既需要体验平滑和业务连续,又能确保风险尽可能低;
- 中期之惑在于“场景爆炸”:多元化的数据应用场景带来需求的复杂化、散乱化;
- 远期之忧在于“范式颠覆”:AI大模型、Agent的兴起,正在彻底改变数据交互、使用的基本逻辑与方式,数据库需要支撑起未来“范式颠覆”带来的变化。
在平凯星辰研发副总裁姚维看来,本质上,数据库的选型长期存在着“水平扩展、业务透明、极致性能”的“不可能三角”,企业一直面临“鱼与熊掌不可同时兼得”的状况。

例如,集中式数据库具备极致的性能和业务透明,但在扩展性方面也存在瓶颈,无法水平扩展容量、性能等;同样,分库分表的分布式数据库具备极佳的扩展性和性能,却也牺牲了业务透明性,且运维困难;云原生分布式数据库解决了水平拓展和业务透明,但在极致性能方面又遇到瓶颈,主要是延迟方面难以满足某些极低延迟要求的业务场景的需求。
更加关键的是,这种“不可能三角”极易让企业往往为了满足不同阶段、不同业务场景,而引入多套不同技术架构、不同品牌的数据库系统,后续直接导致数据孤岛、运维复杂飙升、成本过于高昂等一系列问题。
那么,如何打破数据库选项的“不可能三角”?平凯数据库带来了它的答案。
三把钥匙带来答案
在数据相关技术堆栈日益庞杂的今天,平凯数据库的解决方案解决思路是“为用户做减法”,不额外增加产品,收敛选择路径,“敏捷模式、标准模式、聚能模式”三种部署模式,满足企业不同场景、不同阶段的需求,从而解决数据库选型的难题。
三种部署模式犹如三把钥匙,破解“水平扩展、业务透明、极致性能”的“不可能三角”。姚维直言,三种模式基于同一个原生分布式内核,并非三个独立的产品,而是通过调整计算与数据的“亲和度”,衍生出三种部署形态,用户可根据业务阶段无缝切换,无需迁移数据。

以聚能模式为例,其专为对延迟极度敏感的场景打造。通过内存直连与亲和性调度等技术创新,将延迟降低至原来的 1/4,吞吐提升 2-3 倍,让客户无需牺牲分布式弹性即可享受单机般的极致性能。
“分布式架构通常是将计算与存储分离,做数据切片,尽量追求业务透明和数据分布均匀,这种方式的代价是数据散,在某些需要跨节点处理数据的业务场景中,计算与存储都需要访问网络,容易带来延迟上升。”姚维补充道,“聚能模式的思路是将计算与存储融合,减少跨网络访问内存数据;同时,将关联数据增加数据组调度策略,把它们调度在同一台节点内,类似一台单机数据库,实现极低延迟的极致性能。”
同样,标准模式则是延续经典的存算分离模式,在水平扩展与业务透明性上保持业界标杆水准,完美适配数据量快速增长的成长型与核心业务场景 。
而敏捷模式则专为 TB 级以下数据量及创新业务设计。该模式仅需 1-3 个节点即可起步,读写性能大幅优于 MySQL,压缩率提升 3 倍以上,并提供优于单机主从架构的高可用能力,原生拥有金融级 RPO=0 的强一致高可用,极大降低了客户的试错成本与使用门槛 。
正所谓好的架构与技术,往往让使用者们无感,只需聚焦在业务创新之中。本质上,为了“为用户做减法”,平凯数据库在“给自己做加法”,通过底层内核层面的技术创新,通过计算与存储的聚合与解耦、以及数据组调度机制,实现了数据分布的自适应,从而完成数据库在不同形态之间的灵活切换。
“数据库架构的关键不应该预设为某种‘最优形态’,而需要具备顺应业务变化的动态调整力。”姚维强调,“三种模式彻底打通了业务发展的全生命周期,企业无需在早期即押注重金,而是做到‘随需而变’。”
这一创新在底层逻辑上抹平了“集中式”和“分布式”的界限,打破了传统意义上数据库分类的壁垒,一直以来,从产业视角看,“集中式”和“分布式”被解读为技术路线之争;但站在用户视角,面临的真实困境是“全场景覆盖的不可能三角” ,他们关心的问题其实非常朴素:这个场景下,谁能把问题解决得最好?
有了一套内核三种模式以后,客户可以不再受困于“集中式”还是“分布式”,只需关注当下的适配性,而将未来的不确定性交给模式切换来解决,以最小的代价应对最大的变化。三种模式的本质是将选择权交回用户手中。
内核持续进化,迎接AI长远挑战
信通院《数据库发展研究报告(2025年)》指出,AI技术的快速发展,正驱动数据库架构不断演进,数据库技术已迈入AI原生时代。
无疑,从长远看,AI给数据库带来的颠覆性挑战不容小觑。一方面,AI爆发,带来愈发丰富的事务型、分析型、向量等多种数据类型,需要数据库能够更好和更快的处理;另一方面,Agent的爆发和应用,不仅带来数据库使用逻辑的改变,更可能带来脉冲式的数据流量冲击,甚至会导致海量碎片化实例存在于数据库环境之中。
这些颠覆性的变革正对于数据库的弹性、隔离性与多模支持能力提出前所未有的高要求。因此,数据库内核走向进化,不仅需要支撑起传统业务场景的数据处理需求,更能够匹配未来AI技术应用需求。
对此,平凯数据库的解决思路是充分解耦。在新一代存算分离2.0内核中,平凯数据库着重聚焦两项重要工作:其一,抽象物理存储和IO接口标准化,解决数据库与本地存储紧耦合的问题,让数据库成为一个通用化的数据底座,确保各种数据服务体验的一致性;其二,解耦数据库各个模块,分析引擎、向量引擎和权威索引擎等通过可插拔的方式统一在抽象层之上。
“我们还需要对各个模块进一步拆分,以确保各种任务独立分配资源和彼此之间零干扰。”姚维补充道。此外,平凯数据库还针对AI生态做了大量工作,原生适配AI框架、AI SDK等。
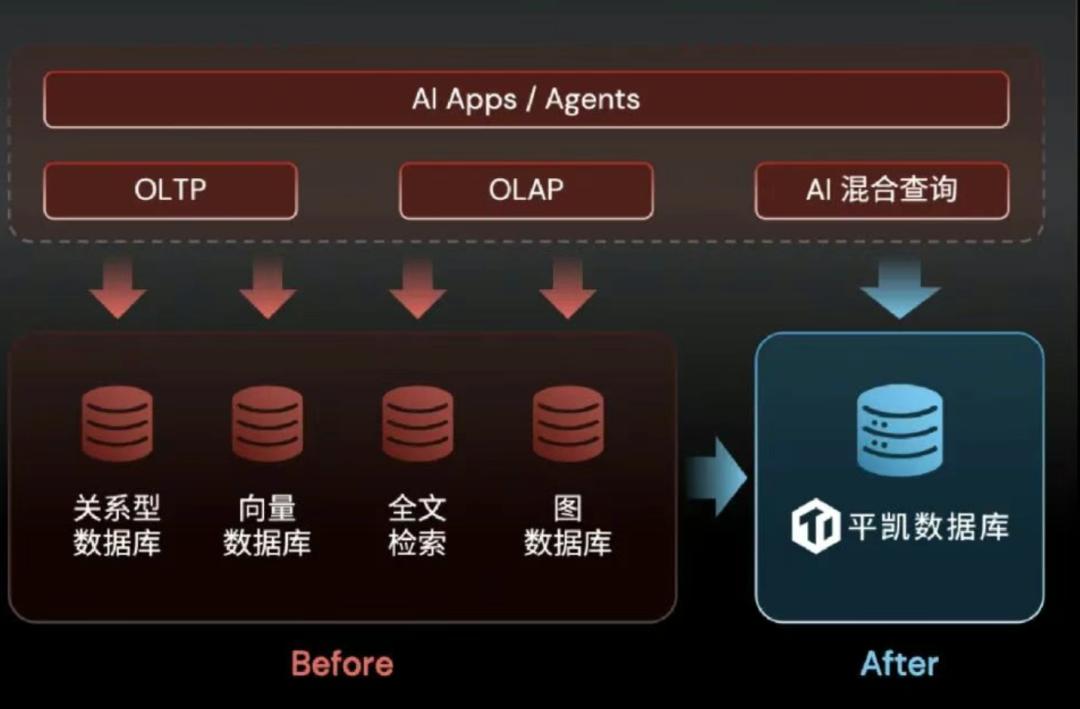
事实上,平凯数据库新一代存算分离2.0内核的能力已经在Manus、Dify等头部热门AI种子用户的真实业务场景中得到验证。例如,Manus利用平凯数据库新一代存算分离2.0内核能力成功支撑起流量暴涨;Dify通过平凯数据库新一代存算分离2.0内核成功部署超过50万个实例,且运维复杂性和成本均大幅下降。
据悉,基于平凯数据库新一代存算分离2.0内核的首款产品是平凯数据库云服务,将于今年上半年正式推出。平凯星辰表示,基于新一代内核的三种模式也很快会推出,无论是私有化部署还是云端环境,均将保持一贯优良的使用体验。
综合观察
信创的本质不是替换,而是进化。
《数据库发展研究报告(2025年)》预测,到2027年,中国数据库市场总规模达到837.42亿元,市场年复合增长率(CAGR)为11.99%,数据库品牌将进一步收敛,市场加速进入高质量发展阶段。过去两年里,平凯数据库首批通过分布式数据库安全可靠评测,并在国内服务超过 500 家大型企业,上线 3500 个关键系统和部署总节点数超过 28,000 个,覆盖金融、运营商、医疗等多个行业。
无疑,过去两年,平凯星辰证明了其多年坚持内核架构技术创新的巨大价值。面向未来,平凯星辰将继续推动“统一数据底座”战略,深耕数据库内核技术,与用户共同进化,让数据库技术不再是业务的枷锁,而成为企业探索智能世界时最坚实的基石。


