
近日,谷歌又出现大面积瘫痪事件,导致全球范围内多款Google服务崩溃,这已经是谷歌近半年第三次出现大规模宕机事件,堪称上演宕机“帽子戏法”。
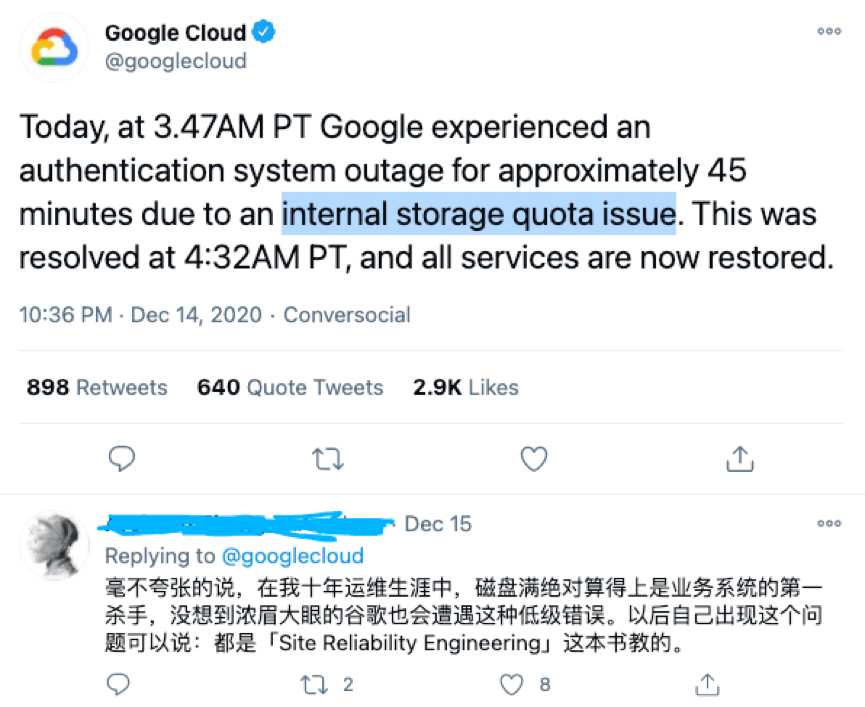
回顾此次宕机事件,谷歌在出现宕机之后的反应倒是挺快。根据谷歌云官方推特表述,经过谷歌运维工程师近50分钟的紧急处理,相关服务在当地时间凌晨4点32分恢复正常,真是“同是天涯运维人,凌晨加班曾相识”。
再来看看此次宕机事件的“元凶”–“internal storage quota issue”,谷歌后续的一份初步调查报告中称:此次宕机的原因是“我们的自动配额管理系统出现了问题,降低了谷歌中央身份管理系统的容量,导致其在全球范围内返回错误。因此,我们无法验证用户请求是否经过认证,并向用户提供错误。”

何谓“自动配额管理”问题?难道之前大部分媒体报道的“磁盘写满”宕机原因都是错的?亦或是“磁盘写满”是表象,“自动配额管理”才是诱因?带着好奇心,大数据在线小编找到了资深存储专家李工,请他详细分析了此次谷歌宕机事件背后的大瓜。
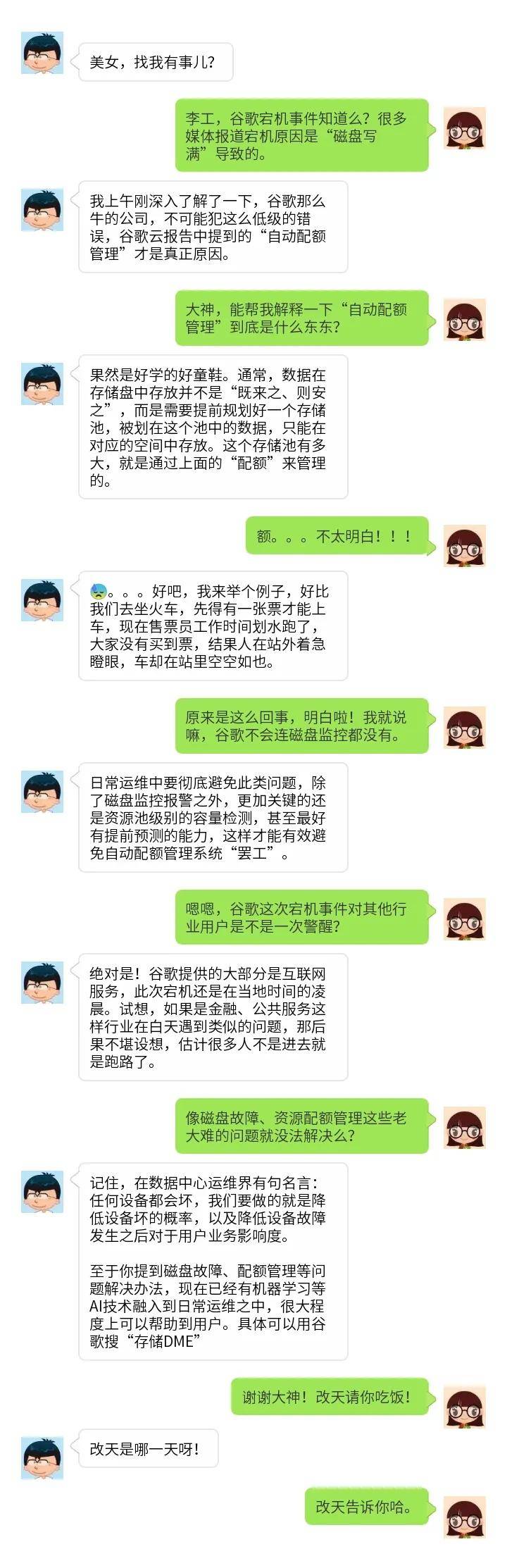
请教完大神之后,小编对数据中心当前运维情况进行了一番调研。现阶段,金融、政务、交通等行业的数据中心,无论是规模、设备数量还是应用种类、复杂性都远胜过去。Gartner首席分析师Pankaj Prasad分析,企业IT基础架构和应用程序所产生的数据量正以每年2-3倍的速度增长,其中像指标、日志等机器所产生的数据类型多样且增长迅速,未来会给运维带来极大挑战。
根据相关调查数据显示,随着全球数据规模的爆炸性增长,在企业数据中心的故障中,存储设备相关故障已经占到70%以上,成为数据中心故障的“主力军”,以某国际互联网社交企业为例,每天需要修复数据24TB,每天因修复带来的跨机架流量高达180TB。并且,近期银行、证券等金融行业也是频频故障瘫痪,有着深厚先进技术积累的科技、金融领域企业尚且在运维上频频触礁,其他领域的风险和困境可想而知。
可以说,解决存储设备故障问题等于给数据中心买来一份“保险”。显然,在数据中心技术和新应用的层出不穷的今天,传统运维依然高度依赖人的经验和人的精力,运维人员就像一群救火队员,不是在解决问题就是在解决问题的路上,以至于好多运维人员感叹自己是操着卖白粉的心赚着卖白菜的钱。。。
如何拯救运维人员于水火之中?彻底解决数据中心复杂化带来的运维复杂化?智能运维绝对是大势所趋,小编也大致分析了一下当前智能运维解决方案的近况。当前,智能运维围绕设备异常、容量预警等关键场景,融入AI相关特性,让运维走向自动化和智能化,但号称智能运维解决方案的多如牛毛,你搜索一下,搞不好是“X田系”搞的……小编又请教了一下存储大牛老李,他说需要从三个方面来衡量一款智能运维解决方案的优劣。
首先需要具备容量预测能力(设备侧+云端均具备)。假设客户能够提前预知阵列或存储池,甚至是更细粒度对象的容量变化趋势,那么容量配额不足导致服务宕机的发生可能性则会大大降低。智能运维解决方案需要云上+本地联动运维能力,并且能够基于时序预测等关键技术,最好可以向客户提供未来最长365天的容量趋势预测,并能够提前预警80%配额,提醒用户提前扩容。
其次需要具备风险盘预测能力(异常检测模型服务提前14天预测硬盘故障),智能运维方案需要每日采集数据中心硬盘数据(硬盘ID、SN、硬盘非安全断电次数、通电时长),从历史数据中识别硬盘不同属性的突变模式对当前状态进行预测,结合用户反馈数据,定期执行模型自优化,持续提升预测精度,并且为数据中心硬盘提供主动运维。风险盘预测能力考验的是方案商的算法模型能力,突变模型服务企业越多、模型训练越久,识别风险故障就越正确。
如果厂商一上来就说自己模型准确率高达99.9%,这十有八九是骗子,劝你赶紧报警。
最后,具备存储性能异常预测管理能力(围绕存储性能相关问题提供全面分析处理方案)。这种能力又分为三块:第一是性能预测及潮汐预警,需要基于时间序列预测等关键技术的性能预测特性以及基于阈值触发的性能潮汐预警,能够让客户预知设备关键性能指标变化趋势(如时延、IOPS、块带宽),提早发现设备性能瓶颈点,辅助客户尽早规避可能发生的异常;
另外,第二是性能异常检测与根因定界分析,针对“传统的专家经验规则或静态阈值预警,无法覆盖大多数性能异常场景,且可能存在误报漏报的情况”,方案可以基于机器学习的关键性能KPI异常检测及根因定界特性,无监督自学习的异常检测模型能够实时检测设备时延是否异常,异常检测准确率越高越好;另外有些厂商在存储设备中内置基于多集成树算法融合模型,外加皮尔逊相关性关联分析算法,实现异常根因的定界分析,大幅提升客户发现性能问题、定位问题边界的效率。
第三就是常见性能故障自修复,有能力将逐步实现异常场景的快速自愈,降低客户运维门槛,降低客户运维成本,实时保障客户业务不受干扰。
小编又进一步调研了当前的市场情况,在众多数据中心智能运维解决方案中,以华为为代表中国厂商的解决方案近年来不断进步,甚至达到了业界领先水平。以华为数据管理引擎DME为例,目前在银行、证券、政府等多个行业广泛应用,在保护用户数据隐私的前提下,有效地帮助金融等行业用户构建构筑端到端的感知能力、智能的分析能力以及可信的执行能力来实现运维自动化闭环,大幅提升运维和资源利用效率。
面向未来,随着智能运维技术的不断成熟与完善,小编相信数据中心运维人员不再是那个忙得四脚朝天的“热锅蚂蚁”,而是故障围困万千重,我自岿然不动,任凭风云起,稳坐钓鱼台,谈笑间,故障已灰飞烟灭。


