
数字世界的发展离不开各种各样的数字工具,Mars则是推动科学计算的强力武器。
在现代科技的演进中,伴随着计算环境的复杂以及数据量的大规模爆发,使得科研人员和开发者往往要面对十分庞大的计算量。比如在金融工程、基因测序、气候研究等领域,不仅需要强大的计算力支持,还要保证数学理论上的抽象与严谨,并兼顾程序设计上的实用与实践。
基于此,阿里巴巴推出基于张量的分布式计算框架Mars,并与英特尔合作,借助英特尔傲腾持久内存提供的更大内存容量与低时延特性,大幅加速科学计算任务中产生的中间过程的数据I/O,明显提升分布式科学计算的运算效率。
分布式计算难以应用于科学计算
基因序列、大自然、宇宙充满了未知的秘密,科学计算就是人类揭开一些隐藏信息的钥匙。在数字化发展逐渐成熟的当下,除了科学研究外,科学计算也为金融、交通、气象等一些工程技术提供了可行方案。
科学计算的过程往往伴随着庞大的数据量以及高计算力需求,因此也诞生了一些专为科学计算而发展的工具,如SciPy。从诞生日起,SciPy已经经历了二十年的发展,作为面向Python的开源科学计算库,SciPy一直是科学计算的核心,并代表着Python的一个行业标准。在SciPy提供的基本算法中,涵盖了现有的数学软件分类系统,可以为微分、积分方程等计算提供完整流程,这也使得SciPy在数学、工程、科学计算等领域发挥着十分重要的作用。
在整个SciPy体系中,Numpy是各种工具的基础,它不仅提供了多维数组的数据结构,还支持SciPy体系中的各种计算。多维数组又叫张量,这个概念在近几年被广泛传播,它是深度学习的基础。张量拥有很多优势特性,相比于二维表/矩阵,张量能够创造更高纬度的矩阵和向量,因此其具有更加强大的表达能力。
在AI创新的驱动下,掀起了一股机器学习和深度学习的热潮,张量的使用也逐渐增加。Numpy由于简洁易用且性能强大,在企业中被广泛应用。不过,Numpy还只适用于单机条件,对于大部分函数都无法进行并行化操作,也不能利用CPU的多核心处理能力来提高计算效率,从而使得Numpy不能突破现有的规模瓶颈。
在这样的背景下,分布式计算引擎的出现为处理海量数据的工作提供了另一种思路。分布式计算是一个十分高效且具备高性价比的方案,在应对大数据集的计算任务中,不仅可以均衡任务调度,还能大幅提高计算效率。
但值得注意的是,分布式计算引擎在科学计算领域并不能发挥太大作用,其原因就是前者的诞生与后者没有必然关系,而分布式计算引擎的上层接口不匹配,导致科学计算任务很难用传统的SQL/MapReduce编写。且在执行过程中,计算引擎本身没有对科学计算进行针对性优化,使得后者的计算效率同样难以满足行业发展需求。
基于此,阿里巴巴推出开源分布式科学计算引擎Mars,将分布式技术引入科学计算领域,突破大数据计算引擎以关系代数为主的计算模型,将大规模的科学计算任务从MapReduce的上千行代码降低到Mars的数行代码,使得科学计算的效率大幅提升。
Mars增强科学计算核心
Mars在科学计算领域的应用是突破性的。作为新一代大规模科学计算引擎,Mars让大数据可以进行高效的科学计算,并将其带入到分布式时代。目前,Mars已经在阿里巴巴及其云上客户的业务和生产场景中广泛应用,帮助用户探索数据背后的价值。
具体来看,Mars具备以下几个独特的优势和特点,使得其在科学计算领域拥有广阔前景:
第一,符合使用习惯的接口,容易上手。Mars通过内部的tensor模块提供兼容Numpy的接口,用户只需要通过import Mars就能将已有的基于Numpy编写的代码移植到Mars中,直接获得比原来扩大数万倍的运算规模。
在实际移植过程中可以发现,代码只需要有少量改变,一是将import numpy改成import mars.tensor;二是通过execute来触发执行。目前,Mars 实现了大约 70% 的常见 Numpy 接口。据悉,在Mars后续的升级迭代中,将逐渐把SciPy技术栈中的工具分布式化,比如提供完全兼容的pandas接口,从而完善整个Mars应用生态。
第二,支持GPU加速,这也是Mars在科学计算领域十分突出的一个优势。用户可以十分简便地设置GPU加速:创建张量时,通过指定gpu=True就可以让后续计算在GPU上执行,进一步提升计算效率。
第三,支持二维稀疏矩阵。通过设定sparse=True,用户可在Mars创建稀疏矩阵,这样的好处是可以节省存储空间,有利于计算效率的提升。
第四,可扩展性。Mars可以向内扩展到单机,也可以向外扩展到有数千台计算机的服务器集群。由于本地和分布式版本都共享相同的代码,因此随着数据的增加从单机迁移到集群也是十分便利的。
粗粒度图
也是基于这些特性和独特的优势,Mars支持多种调度方式,如多线程模式、分布式、单机集群模式,这保证了Mars的扩展性,也让其可以支持更多科学计算的场景。与Numpy相比,Mars可以看成是包含粗粒度图与细粒度图的计算图,给定一个张量,Mars会将其在各个维度划分为小的chunk,然后对这些chunk进行处理,将其调度到多核或者分布式集群中来执行。
这主要是因为Mars不会在客户端进行真正的运算操作,当用户写下代码时,这些数据会在内存中用图的形式来记录下来,并在用户使用execute触发执行后,将图提交到Mars的分布式执行环境中。本质来看,Mars是一个对细粒度、异构图的执行调度系统。
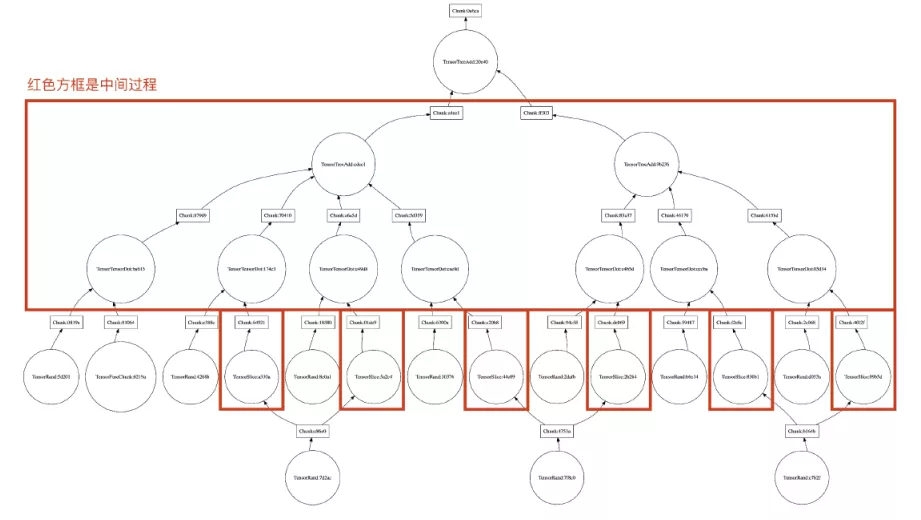
Mars chunk级别的执行图
值得注意的是,尽管在Mars矩阵运算中输入和输出的数据量并不大,但在chunk之后的运行过程会产生大量的中间过程,在上图中,红色框内部的就是产生的中间过程。毫无疑问,这些过程的产生会占用大量内存资源。为此,阿里巴巴在Mars中加入了数据溢出控制手段,将暂时不用或用不到的数据放到磁盘中存储,防止内存溢出,保证计算安全。
英特尔傲腾助力Mars突破计算瓶颈
数据溢出控制手段会有效减少Mars运行时内存资源不必要的消耗,但与此同时,在TCO相当的条件下,内存系统的构建会成为制约Mars计算效率的又一瓶颈。
传统硬盘价位低,且可以提供大量存储空间,但在可靠性、物理空间要求、散热等因素上会带来新的应用成本。且在I/O速度方面,从硬盘访问数据会伴随着严重的延迟,在这一点上,DRAM拥有明显优势,可以减少千倍的延迟时间,但在容量方面又会有新的困扰。
在此背景下,阿里巴巴与英特尔合作,在运行Mars的服务器上配置英特尔傲腾持久内存,通过其容量大、低延迟的特点为Mars提供足够的共享内存,保证Mars科学计算效率的高水平实现。
英特尔傲腾持久内存拥有两种操作模式,内存模式和应用直接模式(AD),前者适用于大内存容量,后者具备非易失性,应用可直接在内存中进行运算,大幅降低堆栈中的复杂程度。不仅如此,英特尔傲腾持久内存可以提供128G、256G、512G容量,与传统DRAM相比每GB的内存成本也更低,可以满足Mars大规模应用的需求。
Mars需要满足不断多样化的科学计算环境,为此,英特尔对傲腾持久内存进行了两个调优,一个是内存启用Snoop for AD模式,一个是Plasma在持久内存中实现共享。前者可以保证傲腾持久内存保持较高的I/O水平,后者让内存资源应用更为合理,从而有效提升Mars的计算性能。
在实验环境下,使用两个矩阵相乘的科学计算为Mars的工作负载,分别采用装配有英特尔傲腾持久内存的服务器和搭载DRAM内存的服务器来执行,在对Mars进行不同数据集的工作负载测试后可以发现,当数据集规模较小时,数据是可以被DRAM缓存的,持久内存的性能接近于DRAM;当数据集规模不断上升后,持久内存的优势开始显现,当数据集规模增大到SF=0.5时,使用傲腾持久内存的性能就有相对于DRAM 1.11倍的提升。
可以说,利用英特尔傲腾持久内存,Mars的计算性能会得到有效提升,尤其是面向大规模数据集时,英特尔傲腾持久内存不仅能解决数据缓存溢出问题,还能大幅降低数据延迟,从而让科学计算更为高效。


