
“五年前,我们很多行业客户的数据还是以ERP、CRM等数据为主,10TB就属于很大的数据量;今天,这些客户积累的数据量通常达到PB级,像行为数据等非结构化数据增长极为迅速,业务形态也发生了巨大变化,基于海量数据的AI应用正在由点到面地铺开”–一位深耕行业的ISV如是说。
的确,从智能推荐、对话机器人,到自动驾驶、风险控制、产品检测,如今AI应用正深入到各行各业之中,对企业降低成本、改善客户体验和洞察市场等方面发挥着巨大作用。IDC最新《全球人工智能支出指南》显示,2021年全球人工智能领域支出将高达853亿美元,未来五年复合年增长则高达24.5%。
不过,随着AI在行业各个场景中多点开花,数据作为关键生产要素的作用愈发突出,海量数据的采集、存储、传输和应用让存储层挑战逐渐放大。可以说,数据存储挑战已然是AI应用之路上最大的拦路虎,如何最大限度地挖掘数据价值和推动AI应用落地,关键在于解决数据存储的挑战。

那么,AI应用场景的数据具有什么样的特点,又会带来哪些典型的存储问题?面对AI应用带来的性能、容量和成本挑战,我们又如何对症下药?Hitachi Vantara的Hitachi Content Software for File为何要将对象存储与文件存储整合在一起,这种举措对于解决AI带来的存储挑战有何重要价值?
下面让我们一探究竟。
AI应用开启新局面
过去,应用和场景通常是围绕着业务流程展开;如今,几乎所有的智慧应用都是通过数据和算法来驱动。
随着数据被官方确认为生产要素,AI应用正加速开启新局面。像《十四五规划》全文中,跟“智能”、“智慧”相关表述就高达57处,AI正成为中国数字经济高质量发展的核心驱动力之一,愈发深度融入产业数字化和企业数字化转型之中。
以华南地区的制造业工厂为例,为了提升产品质量和检测效率,大量工厂都在产线之中部署了AI检测应用;如手机生产流程中每个环节都会进行拍摄,并利用AI算法对其进行不断的学习与训练,实现大幅降低产品瑕疵率,并提升检测效率。

在金融领域,AI也正深刻改变业务场景。以保险行业为例,RPA机器人、智能推荐、语音识别、图像识别等大量融入到业务场景之中,对业务效率提升、成本下降和用户体验改善大有裨益。
在政府、能源、交通等多个行业,AI也正成为重要的生产力工具。Gartner认为,到2024年,将会有高达75%的企业将从试点转型运营AI。而随着AI深入到更多业务场景之中,整个市场也呈现出新的趋势:
- 企业需要更多高质量的模型和与之相匹配的业务场景;
- 随着AI/分析型应用的丰富,数据驱动决策成为可能;
- 数据丰富程度将有利于企业构建完整和正确的视图,再利用AI技术来实现营销、服务等的改善,真正实现以客户为中心;
- 企业对于数据采集、存储、管理和安全等合规性要求会越来越高。
因此,越来越多企业在AI应用中感受到数据所带来的挑战,而且这种挑战跟以往很不一样。
数据不该成为AI拦路虎
在了解AI应用带来的数据挑战之前,我们需要清楚AI应用场景会产生什么样的数据、这些数据具有什么特点、AI应用对于数据存储都会有哪些要求。

事实上,当前大量的AI/分析型场景之中,海量非结构化数据已经成为常态,每张图片/每个文件通常很小,但数量级极高。像在金融行业,金融业务不仅有大量原始票据通过扫描形成图片和描述信息文件,还有电子合同、签名数据、人脸识别数据等,金融行业影像数据一般单个文件大小为几KB或几百KB,非结构化数据的数量甚至可以高达数十亿级规模,并且还在逐年增长。
具体到AI应用的环境,首先数据需要进行准备和清洗,将原始数据去重、去除格式错误、去除错误数据和启发式回填,将数据转换为机器学习模型所需要的格式,这个处理阶段通常具有典型I/O极其密集的特征,需要数据缓存基础设施实时执行。
进入到AI训练阶段,以机器学习经常用到的DNN(深度神经网络)为例,像卷积神经网络、循环神经网络等都是模型复杂的深度神经网络,并且需要利用高度并行的技术来实现,这些模型需要大量经过清洗和标记的数据来训练,通常数据集的大小是PB级,涉及到大量的随机、小型(KB)级读取操作,对于存储的吞吐量、延迟要求极高。

以OpenAI去年发布的GPT-3模型为例,模型参数高达1750亿个,预训练数据量高达45TB,最大层数高达96层,无论是模型规模、数据量、训练层数都呈现指数级的增长趋势。
当AI进入到推理和模型部署阶段,对于数据延迟又非常敏感,所部署的训练好的模型需要近乎实时化分析数据,对于数据存储性能要求极高。此外,部署模型中所处理的数据都需要重新存储,并与训练数据重新整合,进而让模型不断训练、改进和优化,这个过程对于数据存储系统的性能、容量也是极大考验。
综合来看,过去的存储系统在存储架构、元数据管理、缓存管理等环节都是为传统业务场景而设计。进入到AI时代,面对海量非结构化数据场景,传统存储在性能、容量、扩展性、成本等方面都捉襟见肘,很难胜任各种AI应用的要求。
HCSF:为AI应用提速
事实上,如果仔细分析AI应用涉及到的数据采集、整合、传输、存储、管理和应用,会发现当前很多企业往往是通过选择不同架构的数据存储产品来满足需求,造成在性能、可扩展性和易用性之间妥协。
例如,为了满足扩展性和容量的需求,很多企业之前会尝试部署横向扩展NAS,但是传统NAS几乎都是为大文件场景而设计,对于AI应用涉及到的海量小文件场景非常容易造成性能瓶颈;而为了速度,通常会选择基于块的全闪阵列,但是规模和共享方面又会受到限制。
那么,针对AI应用,在数据存储层面能否通过一套方案覆盖AI应用所有存储工作流,并且能够全面平衡性能、扩展性、容量、易用性和成本?如今,Hitachi Vantara的Hitachi Content Software for File(HCSF)为我们打开了新思路,提供了一种切实可行的方案。
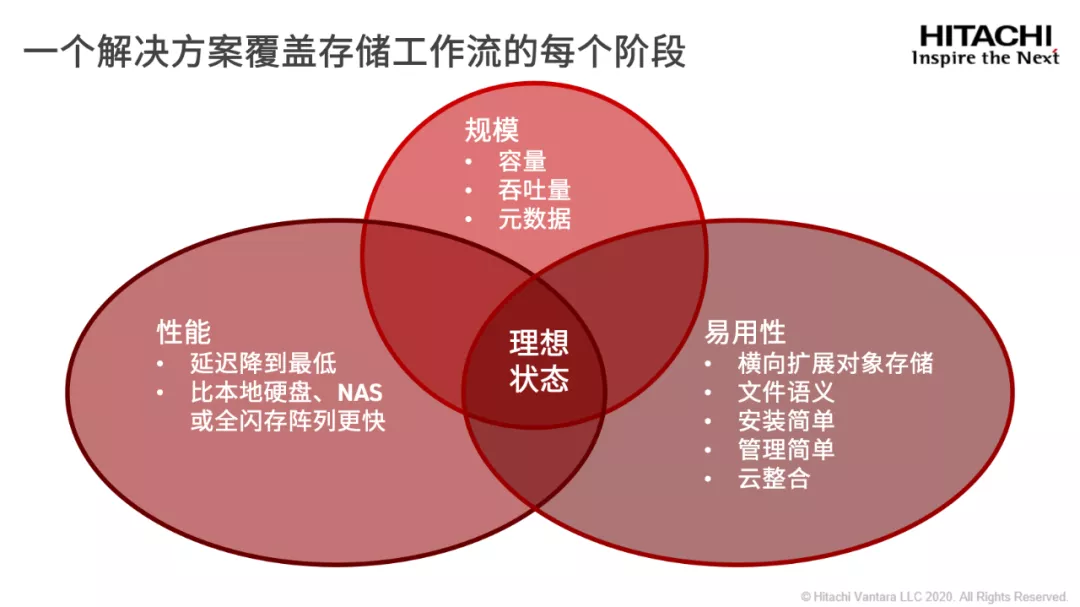
首先,作为全新的分布式文件系统和管理解决方案,Hitachi Content Software for File专为AI/分析型应用等超高性能和大容量应用而设计,充分发挥分布式文件系统和对象存储的优势,采用共享存储架构来消除性能瓶颈,可以轻松、独立地扩展计算和存储资源,并且利用紧耦合的单一解决方案,提供与硬件设备类似的高性能体验。
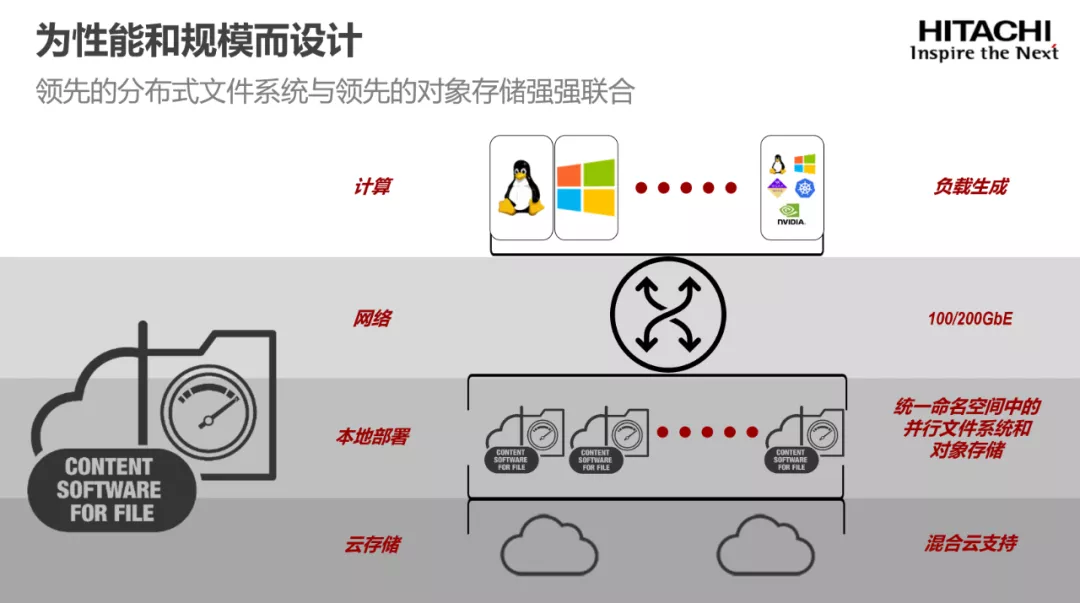
例如,用户将NVMe高性能存储和对象存储进行完美集成,通过Weka文件系统可以独立扩展性能和容量:如果需要更强的性能,通过扩展NVMe存储即可;而如果需要更多容量,添加更多对象存储即可。
其次,Hitachi Content Software for File为整个数据管理提供单一平台,实现了基于元数据的数据管理自动化和智能化,实现跨越边缘、核心和云的数据管理,消除数据孤岛和多副本情况,单一命名空间也无需管理各层之间的数据移动,大幅简化了AI应用带来的复杂数据管理工作。
另外,Hitachi Content Software for File还拥有出色的灵活性,具备可以对接云的扩展能力。例如,HCSF的快照功能,可以推送到任何S3对象存储,将快照数据存储在云中,以方便日后使用,让基础设施根据应用状况来随时调整工作负载资源,变得更加敏捷和灵活,广泛满足人工智能、机器学习和分析型程序的需求。
总体来看,Hitachi Content Software for File切中了当前AI应用的数据存储痛点,实现了数据存储在性能、容量、扩展性、易用性和成本之间的平衡。面向未来,随着企业数字化转型的逐渐深入,会有越来越多AI应用成为企业的核心业务,数据存储不应该成为AI应用的拦路虎,而Hitachi Content Software for File解决方案的推出,有望帮助企业进一步释放数据潜力,也必然会给企业数字化转型和AI应用全面落地带来更多价值。


